 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELSA: An ELastic SNN Inference Architecture for Efficient Neuromorphic Computing
May 20, 2026Spiking neural networks (SNNs) exploit event-driven and addition-only computation to substantially improve efficiency for intelligent computation. A key temporal property of SNNs, elastic inference, allows outputs to emerge progressively, enabling responses to salient inputs much earlier than full evaluation. However, existing SNN-specific accelerators cannot capitalize on this property. Layer-by-layer designs emit outputs only after all layers are complete, while time-step-by-time-step designs rely on coarse-grained, layer-wise pipelines that require synchronizing all spines/tokens within a layer. This barrier prevents results from being forwarded immediately, delaying the earliest possible response and forfeiting the benefits of elastic inference. To address these challenges, we propose ELSA, a near-SRAM dataflow architecture that realizes true elastic inference through a fine-grained spine/token-wise pipeline and hardware optimizations tailored to SNNs. ELSA forwards each spine/token immediately upon production, forming a continuous streaming pipeline that substantially reduces the latency to the first response. To enhance this lightweight execution, ELSA introduces a bundled address event representation protocol to lower communication traffic of network-on-chip (NoC), and leverages mini-batch spiking Gustavson-product to cut memory access and exploit inherent sparsity. Combined with mapping and scheduling optimizations, ELSA achieves efficient, event-driven computation without compromising accuracy. Experiments show that SNNs can outperform quantized artificial neural networks (QANNs) while maintaining on-par accuracy. For a 4-bit ResNet-50, ELSA achieves 3.4$\times$ speedup and 13.6$\times$ higher energy efficiency over the SOTA QANN accelerator (ANT), and 2.9$\times$ speedup and 22.1$\times$ energy efficiency gains over the SOTA SNN accelerator (PAICORE).
Determinism in the Undetermined: Deterministic Output in Charge-Conserving Continuous-Time Neuromorphic Systems with Temporal Stochasticity
Mar 16, 2026Achieving deterministic computation results in asynchronous neuromorphic systems remains a fundamental challenge due to the inherent temporal stochasticity of continuous-time hardware. To address this, we develop a unified continuous-time framework for spiking neural networks (SNNs) that couples the Law of Charge Conservation with minimal neuron-level constraints. This integration ensures that the terminal state depends solely on the aggregate input charge, providing a unique cumulated output invariant to temporal stochasticity. We prove that this mapping is strictly invariant to spike timing in acyclic networks, whereas recurrent connectivity can introduce temporal sensitivity. Furthermore, we establish an exact representational correspondence between these charge-conserving SNNs and quantized artificial neural networks, bridging the gap between static deep learning and event-driven dynamics without approximation errors. These results establish a rigorous theoretical basis for designing continuous-time neuromorphic systems that harness the efficiency of asynchronous processing while maintaining algorithmic determinism.
Obtaining Optimal Spiking Neural Network in Sequence Learning via CRNN-SNN Conversion
Aug 18, 2024



Spiking neural networks (SNNs) are becoming a promising alternative to conventional artificial neural networks (ANNs) due to their rich neural dynamics and the implementation of energy-efficient neuromorphic chips. However, the non-differential binary communication mechanism makes SNN hard to converge to an ANN-level accuracy. When SNN encounters sequence learning, the situation becomes worse due to the difficulties in modeling long-range dependencies. To overcome these difficulties, researchers developed variants of LIF neurons and different surrogate gradients but still failed to obtain good results when the sequence became longer (e.g., $>$500). Unlike them, we obtain an optimal SNN in sequence learning by directly mapping parameters from a quantized CRNN. We design two sub-pipelines to support the end-to-end conversion of different structures in neural networks, which is called CNN-Morph (CNN $\rightarrow$ QCNN $\rightarrow$ BIFSNN) and RNN-Morph (RNN $\rightarrow$ QRNN $\rightarrow$ RBIFSNN). Using conversion pipelines and the s-analog encoding method, the conversion error of our framework is zero. Furthermore, we give the theoretical and experimental demonstration of the lossless CRNN-SNN conversion. Our results show the effectiveness of our method over short and long timescales tasks compared with the state-of-the-art learning- and conversion-based methods. We reach the highest accuracy of 99.16% (0.46 $\uparrow$) on S-MNIST, 94.95% (3.95 $\uparrow$) on PS-MNIST (sequence length of 784) respectively, and the lowest loss of 0.057 (0.013 $\downarrow$) within 8 time-steps in collision avoidance dataset.
Scaling Virtual World with Delta-Engine
Aug 11, 2024In this paper, we focus on \emph{virtual world}, a cyberspace where people can live in. An ideal virtual world shares great similarity with our real world. One of the crucial aspects is its evolving nature, reflected by the individuals' capacity to grow and thereby influence the objective world. Such dynamics is unpredictable and beyond the reach of existing systems. For this, we propose a special engine called \emph{Delta-Engine} to drive this virtual world. $\Delta$ associates the world's evolution to the engine's expansion. A delta-engine consists of a base engine and a neural proxy. Given an observation, the proxy generates new code based on the base engine through the process of \emph{incremental prediction}. This paper presents a full-stack introduction to the delta-engine. The key feature of the delta-engine is its scalability to unknown elements within the world, Technically, it derives from the prefect co-work of the neural proxy and the base engine, and the alignment with high-quality data. We an engine-oriented fine-tuning method that embeds the base engine into the proxy. We then discuss a human-AI collaborative design process to produce novel and interesting data efficiently. Eventually, we propose three evaluation principles to comprehensively assess the performance of a delta engine: naive evaluation, incremental evaluation, and adversarial evaluation. Our code, data, and models are open-sourced at \url{https://github.com/gingasan/delta-engine}.
BKDSNN: Enhancing the Performance of Learning-based Spiking Neural Networks Training with Blurred Knowledge Distillation
Jul 12, 2024



Spiking neural networks (SNNs), which mimic biological neural system to convey information via discrete spikes, are well known as brain-inspired models with excellent computing efficiency. By utilizing the surrogate gradient estimation for discrete spikes, learning-based SNN training methods that can achieve ultra-low inference latency (number of time-step) emerge recently. Nevertheless, due to the difficulty in deriving precise gradient estimation for discrete spikes using learning-based method, a distinct accuracy gap persists between SNN and its artificial neural networks (ANNs) counterpart. To address the aforementioned issue, we propose a blurred knowledge distillation (BKD) technique, which leverages random blurred SNN feature to restore and imitate the ANN feature. Note that, our BKD is applied upon the feature map right before the last layer of SNN, which can also mix with prior logits-based knowledge distillation for maximized accuracy boost. To our best knowledge, in the category of learning-based methods, our work achieves state-of-the-art performance for training SNNs on both static and neuromorphic datasets. On ImageNet dataset, BKDSNN outperforms prior best results by 4.51% and 0.93% with the network topology of CNN and Transformer respectively.
SpikeZIP-TF: Conversion is All You Need for Transformer-based SNN
Jun 05, 2024



Spiking neural network (SNN) has attracted great attention due to its characteristic of high efficiency and accuracy. Currently, the ANN-to-SNN conversion methods can obtain ANN on-par accuracy SNN with ultra-low latency (8 time-steps) in CNN structure on computer vision (CV) tasks. However, as Transformer-based networks have achieved prevailing precision on both CV and natural language processing (NLP), the Transformer-based SNNs are still encounting the lower accuracy w.r.t the ANN counterparts. In this work, we introduce a novel ANN-to-SNN conversion method called SpikeZIP-TF, where ANN and SNN are exactly equivalent, thus incurring no accuracy degradation. SpikeZIP-TF achieves 83.82% accuracy on CV dataset (ImageNet) and 93.79% accuracy on NLP dataset (SST-2), which are higher than SOTA Transformer-based SNNs. The code is available in GitHub: https://github.com/Intelligent-Computing-Research-Group/SpikeZIP_transformer
CLLMs: Consistency Large Language Models
Mar 08, 2024



Parallel decoding methods such as Jacobi decoding show promise for more efficient LLM inference as it breaks the sequential nature of the LLM decoding process and transforms it into parallelizable computation. However, in practice, it achieves little speedup compared to traditional autoregressive (AR) decoding, primarily because Jacobi decoding seldom accurately predicts more than one token in a single fixed-point iteration step. To address this, we develop a new approach aimed at realizing fast convergence from any state to the fixed point on a Jacobi trajectory. This is accomplished by refining the target LLM to consistently predict the fixed point given any state as input. Extensive experiments demonstrate the effectiveness of our method, showing 2.4$\times$ to 3.4$\times$ improvements in generation speed while preserving generation quality across both domain-specific and open-domain benchmarks.
Model Extraction Attacks on Split Federated Learning
Mar 13, 2023



Federated Learning (FL) is a popular collaborative learning scheme involving multiple clients and a server. FL focuses on protecting clients' data but turns out to be highly vulnerable to Intellectual Property (IP) threats. Since FL periodically collects and distributes the model parameters, a free-rider can download the latest model and thus steal model IP. Split Federated Learning (SFL), a recent variant of FL that supports training with resource-constrained clients, splits the model into two, giving one part of the model to clients (client-side model), and the remaining part to the server (server-side model). Thus SFL prevents model leakage by design. Moreover, by blocking prediction queries, it can be made resistant to advanced IP threats such as traditional Model Extraction (ME) attacks. While SFL is better than FL in terms of providing IP protection, it is still vulnerable. In this paper, we expose the vulnerability of SFL and show how malicious clients can launch ME attacks by querying the gradient information from the server side. We propose five variants of ME attack which differs in the gradient usage as well as in the data assumptions. We show that under practical cases, the proposed ME attacks work exceptionally well for SFL. For instance, when the server-side model has five layers, our proposed ME attack can achieve over 90% accuracy with less than 2% accuracy degradation with VGG-11 on CIFAR-10.
ResSFL: A Resistance Transfer Framework for Defending Model Inversion Attack in Split Federated Learning
May 09, 2022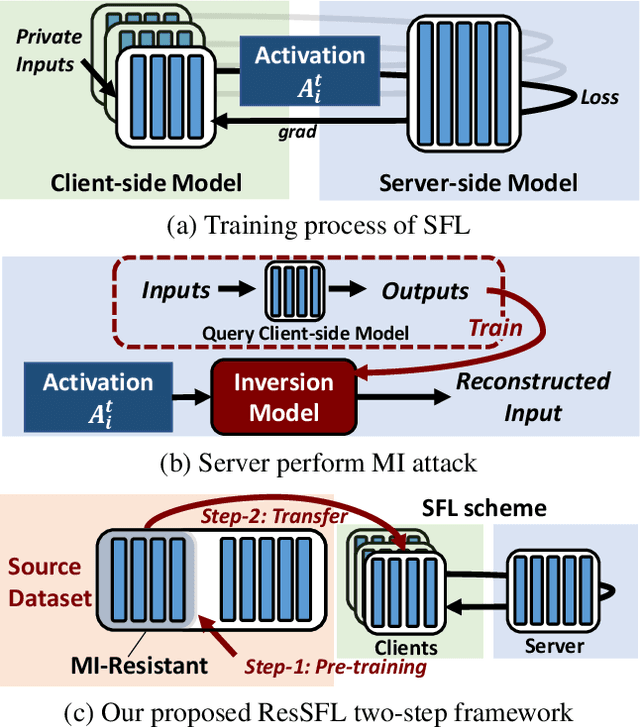
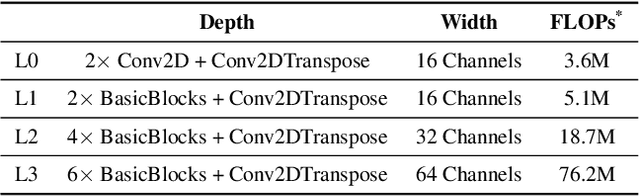
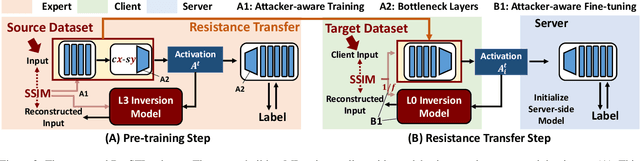
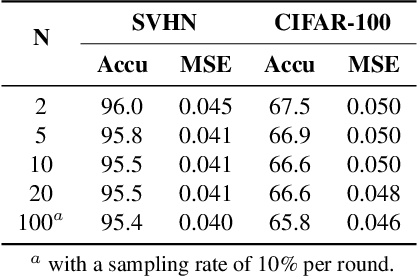
This work aims to tackle Model Inversion (MI) attack on Split Federated Learning (SFL). SFL is a recent distributed training scheme where multiple clients send intermediate activations (i.e., feature map), instead of raw data, to a central server. While such a scheme helps reduce the computational load at the client end, it opens itself to reconstruction of raw data from intermediate activation by the server. Existing works on protecting SFL only consider inference and do not handle attacks during training. So we propose ResSFL, a Split Federated Learning Framework that is designed to be MI-resistant during training. It is based on deriving a resistant feature extractor via attacker-aware training, and using this extractor to initialize the client-side model prior to standard SFL training. Such a method helps in reducing the computational complexity due to use of strong inversion model in client-side adversarial training as well as vulnerability of attacks launched in early training epochs. On CIFAR-100 dataset, our proposed framework successfully mitigates MI attack on a VGG-11 model with a high reconstruction Mean-Square-Error of 0.050 compared to 0.005 obtained by the baseline system. The framework achieves 67.5% accuracy (only 1% accuracy drop) with very low computation overhead. Code is released at: https://github.com/zlijingtao/ResSFL.
CP-ViT: Cascade Vision Transformer Pruning via Progressive Sparsity Prediction
Mar 09, 2022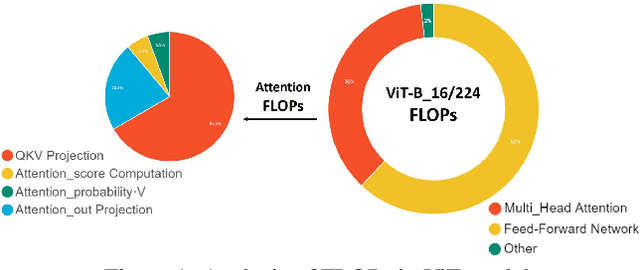
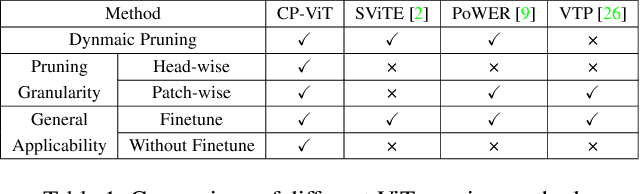
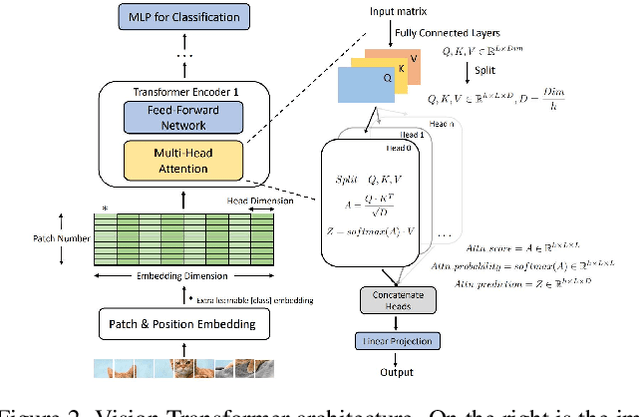
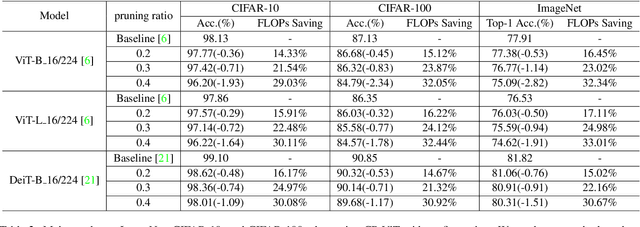
Vision transformer (ViT) has achieved competitive accuracy on a variety of computer vision applications, but its computational cost impedes the deployment on resource-limited mobile devices. We explore the sparsity in ViT and observe that informative patches and heads are sufficient for accurate image recognition. In this paper, we propose a cascade pruning framework named CP-ViT by predicting sparsity in ViT models progressively and dynamically to reduce computational redundancy while minimizing the accuracy loss. Specifically, we define the cumulative score to reserve the informative patches and heads across the ViT model for better accuracy. We also propose the dynamic pruning ratio adjustment technique based on layer-aware attention range. CP-ViT has great general applicability for practical deployment, which can be applied to a wide range of ViT models and can achieve superior accuracy with or without fine-tuning. Extensive experiments on ImageNet, CIFAR-10, and CIFAR-100 with various pre-trained models have demonstrated the effectiveness and efficiency of CP-ViT. By progressively pruning 50\% patches, our CP-ViT method reduces over 40\% FLOPs while maintaining accuracy loss within 1\%.